This is Part 1 of a two-part series. Part 1 (this post) covers the performance and sizing story: how to size a replica, why subprocesses are the unit of cost, and what “Hybrid Sessions” actually buys you. Part 2 covers the security story — permission posture, container hardening, prompt-injection defenses, and an opt-in credential boundary.
Table of Contents
- Background
- The right mental model
- I kept hitting OOM during testing
- Picking a per-turn number
- Gate on active turns, not open sessions
- What about a shared subprocess pool?
- The four hosting patterns from Anthropic’s docs
- Sizing your replica
- Operational gotchas
- Wrapping up
Background
I built HoloDeck — a YAML-driven platform for defining AI agents — and after going all-in on Claude Agent SDK as the first-class backend, one question has dogged me for two months: how do you actually size this thing for production?
The SDK gives you everything you want as a developer. Bash, file I/O, MCP tools, hooks, subagents, structured output. But under the hood it spawns a Node.js subprocess for every turn, and that subprocess has a real memory cost. Run an HTTP endpoint that serves multiple users — AG-UI, REST, whatever — and you need to know how many concurrent turns your replica can handle before the kernel sends a SIGKILL.
Anthropic published an SDK hosting guide with four deployment patterns and one conservative recommendation: 1 GiB RAM per agent instance. Good starting point. Also leaves a lot of questions open. What goes in that 1 GiB? How does it scale with concurrency? What breaks first when you undersize? I had to find out the hard way.
This post is what I wish I’d known before I started shipping.
The right mental model
Diagramming it made it easier to grasp:
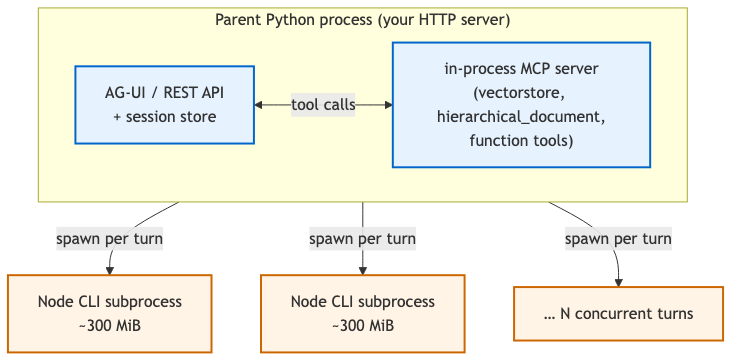
Two facts about this picture mattered:
Tools run in the parent, not the subprocess. claude-agent-sdk exposes create_sdk_mcp_server which lets you host MCP tools in-process — the SDK then forwards tool calls from the subprocess back to your Python process over IPC. So a heavy retrieval tool (qdrant client, chunked corpus, hybrid search index) inflates the parent baseline, not the subprocess. The subprocess is mostly the Claude CLI itself plus V8 runtime.
Subprocesses are per-turn, not per-session. When I first read the SDK source I assumed each session held a long-lived subprocess. It doesn’t — at least not in the pattern I now use. Calling query(resume=session_id) spawns a fresh subprocess that reads the session’s JSONL transcript from disk, runs one turn, and exits. Idle sessions cost essentially nothing — a Python object and a file handle. Concurrent active turns are what eats memory.
Most people miss the second point. The question to ask isn’t “how many users can be connected?” — it’s “how many users can be mid-turn at once?”
I kept hitting OOM during testing
Skipping to the data.
I’m running the agent on Azure Container Apps with 1 CPU / 2 GiB per replica. After implementing per-turn subprocess spawning (Anthropic calls this the “Hybrid Sessions” pattern in their hosting docs), I ran a back-to-back concurrency burst: 5 simultaneous AG-UI calls, twice, ~60 seconds apart.
The first burst — cold start, no held sessions — ran 4 turns successfully and rejected 1 with HTTP 429. Roughly what my (then-naive) memory math predicted.
The second burst — warm, 5 idle sessions still in the store from burst #1 — exited with code 137 within 7 seconds. SIGKILL by the kernel OOM killer.
What killed it:
parent_baseline (~275 MiB)
+ 5 idle sessions (~150 MiB, 30 MiB each)
+ 4 concurrent active turns × ~400 MiB instantaneous peak
───────────────────────────────────────────
≈ 2025 MiB → over the 2 GiB cgroup limit → BOOMThree things I hadn’t appreciated:
- Idle sessions aren’t free. The subprocess is gone but the Python session object and the JSONL file handle stick around. 30 MiB each is small, but at 50 open sessions it’s a real chunk of your baseline.
- Startup peaks stack. When four Node CLIs cold-start at once, their V8 initial-heap allocations land on top of each other. The 1-minute Azure metric showed ~125 MiB/turn; the instantaneous peak that triggered OOM was closer to 400 MiB/turn.
- Cloud-provider memory metrics lie about peaks.
WorkingSetBytesis averaged over a minute. The peak the kernel actually OOM-kills against is the instantaneous resident set, which can easily be 1.5–2× the rolling average.
Picking a per-turn number
After the OOM I had enough data points to settle on a conservative default. The data:
| Observation | Source | Value |
|---|---|---|
| Idle parent, 0 sessions | post-startup /health | ~275 MiB |
| Idle parent, 5 open sessions | post-burst | ~400 MiB |
| 1-min average during 3 concurrent turns | Azure WorkingSetBytes | ~656 MiB |
| Implied 1-min per-turn average | (656 − 275) / 3 | ~127 MiB/turn |
| Instantaneous peak ceiling | OOM at 4 concurrent + 5 idle | > 2 GiB total |
| Anthropic’s per-instance guidance | hosting docs | 1 GiB |
The per-turn number I use now is 500 MiB. How I got there:
- ~300 MiB Node CLI steady state (what you’d see running one turn at a time, slowly)
- +100 MiB simultaneous-startup spike (V8 initial heap allocation stacking)
- +50–100 MiB parent-side transient work charged per turn (hybrid search, rerank, context generation)
- Round up to 500. A bit more conservative than the data strictly requires, but it leaves slack for the things you can’t measure cleanly: GC variance, OS page cache pressure, tool jitter.
On a 2 GiB replica that lands (2048 − 400) / 500 = 3 concurrent turns — which matches the empirically safe ceiling I observed before the OOM. It also scales linearly: 7 concurrent turns on 4 GiB, 15 on 8 GiB.
If your agent is thinner (no in-process retrieval, no MCP servers with persistent state) you can dial this down to ~300 MiB. If it’s heavier (local rerank model, multiple MCP servers, embedded models), bump it up to 700–900.
Gate on active turns, not open sessions
My first capacity gate was the obvious one: cap the number of open sessions. It was wrong.
Under Hybrid Sessions, an idle open session costs ~30 MiB. A mid-turn open session costs ~500 MiB. Same counter, two completely different memory profiles. The thing that actually OOMs you is concurrent active turns — and those are bounded by how fast Claude responds, not by how many users have an open connection.
So the gate I ended up with is a BoundedSemaphore around the SDK query() call:
async def send(self, prompt: str) -> ExecutionResult:
if not self._try_acquire_turn_slot():
return _capacity_exceeded() # HTTP 429
try:
return await self._invoke_query(prompt)
finally:
self._release_turn_slot()_try_acquire_turn_slot() does an atomic check-and-decrement on the semaphore’s counter (asyncio is single-threaded, so a no-await block is genuinely atomic). The first version I wrote used if sem.locked(): return 429; async with sem.acquire(): ... — that’s racy under burst load because between locked() and acquire() other coroutines can grab the slot, and you end up queuing instead of rejecting. Atomic try-acquire fixes it.
The behaviour I want at capacity is shed, not queue. Subprocess startup is expensive and unpredictable; a request that queues for 30 seconds then runs another 40 seconds is worse than a fast 429 the client can retry with backoff. Anthropic’s hosting docs recommend the same.
What about a shared subprocess pool?
This was my next “clever idea” after the OOM. Why spawn a fresh subprocess for every turn? Why not pool them and route concurrent turns to the same long-lived subprocess?
I went looking through the official SDK hosting documentation for a supported pattern. There isn’t one.
The four patterns Anthropic documents — Ephemeral, Long-Running, Hybrid Sessions, Single Containers — all model the subprocess as per-instance or per-turn. Never pooled across concurrent turns. The reason becomes obvious once you think about it: the Claude CLI maintains in-process state (conversation buffer, tool-call cursor, hook registrations) that isn’t safe to multiplex. The SDK’s IPC protocol assumes one in-flight request at a time. Sharing a subprocess across concurrent turns would either serialize them (defeating the pool) or corrupt state (defeating reliability).
The right scaling axis is horizontal. More replicas, each with its own per-turn cap, fronted by your normal HTTP load balancer. Container Apps, Cloud Run, Kubernetes — they all do this trivially.
The four hosting patterns from Anthropic’s docs
For reference, the four patterns the SDK docs describe, with the trade-off I care about most:
| Pattern | Subprocess lifecycle | Memory cost | Best for |
|---|---|---|---|
| Ephemeral | One subprocess per request, exits | Low avg, high startup tax | Low-traffic CLIs, cron jobs |
| Long-Running | One subprocess held per session | High idle cost (300+ MiB/session) | Few concurrent users, sticky sessions |
| Hybrid Sessions | Per-turn subprocess + JSONL transcript on disk | Low idle, peak-only active | Multi-user HTTP services |
| Single Containers | One container per session | Highest isolation, highest cost | Per-tenant compliance / sandboxing |
I run Hybrid Sessions and it’s the right default for almost any web-facing service. The other three exist for genuine reasons but are minorities of the deployment space.
Sizing your replica
Given a 400 MiB parent baseline and 500 MiB per concurrent active turn:
| Replica memory | Derived turn cap | Notes |
|---|---|---|
| 1 GiB | 1 | Bare minimum |
| 2 GiB | 3 | Sweet spot for small services |
| 4 GiB | 7 | Comfortable production tier |
| 8 GiB | 15 | High-concurrency tier |
Past 8 GiB the math keeps working, but you almost certainly want to scale horizontally instead. More small replicas give you better failure isolation, faster autoscale up-and-down, and they spread your subprocess startup tax across more machines.
Operational gotchas
A few things that bit me that I’ll save you from:
1. Metrics lie about peaks. Wire up an OTel gauge for in-flight active turns and alert on it directly. Don’t trust the cloud provider’s WorkingSetBytes for peak detection.
2. Liveness probes can mask OOM. If your container’s liveness probe is on /health and /health doesn’t actually load anything, it’ll pass right up to the moment the kernel OOM-kills the process. You won’t see degradation in the probe data — just sudden exit code 137. Watch the container exit-reason metric, not just probe latency.
3. Subprocess startup is your tail latency. First request after a cold deploy is 40–70 seconds (image pull + tool init + first turn’s subprocess cold start). Subsequent requests are sub-10s. If you have strict p99 SLOs, set min_replicas: 1 and accept the always-on cost; scale-to-zero is a false economy for SDK-based services.
4. JSONL transcripts grow without bound. Hybrid Sessions persists every turn as a JSONL line on disk. If your container has ephemeral storage, this is fine — sessions disappear with the container. If you mount durable storage, you need a retention policy. I haven’t built one yet; for me, ephemeral has been the right call.
5. Tools-in-parent means tool memory is amortized. A vectorstore tool loaded into the parent serves every turn without re-loading. This is a feature — it’s why subprocess spawning is cheap-ish — but it means parent baseline scales with tool count. A single replica running five agents will need a bigger baseline than five replicas each running one agent.
Wrapping up
The Claude Agent SDK is the best agent runtime I’ve used. The production story is solid once you internalize three things: active turns drive memory, the subprocess model is intentional, horizontal scaling is the answer to concurrency. The 500 MiB-per-turn / 400 MiB-baseline budget gives you a defensible starting point on any modern container platform.
If you’re shipping a Claude Agent SDK service and you’ve hit OOMs or you’re guessing at replica size, start there. Tune from real observations, not vibes.
The HoloDeck-side implementation lives in src/holodeck/serve/server.py and the cgroup-aware sizing math is in src/holodeck/lib/runtime.py. PRs and OOM stories both welcome.
Next: Part 2 — Securing the Claude Agent SDK in Production covers what happens after you’ve stopped the OOMs: locking down the permission system, hardening the container, defending against prompt injection, and (opt-in) moving credentials out of the agent’s process environment entirely.
